Jo Diercks von Cyquest beschäftigt sich in seinem Blog hin und wieder kritisch, oder besser gesagt realistisch, mit dem bunten Treiben in der Welt der künstlichen Intelligenz aus der Recruiting Perspektive. Kürzlich ging es um das Thema der automatisierten Bewerber- und Mitarbeiterbewertungen.
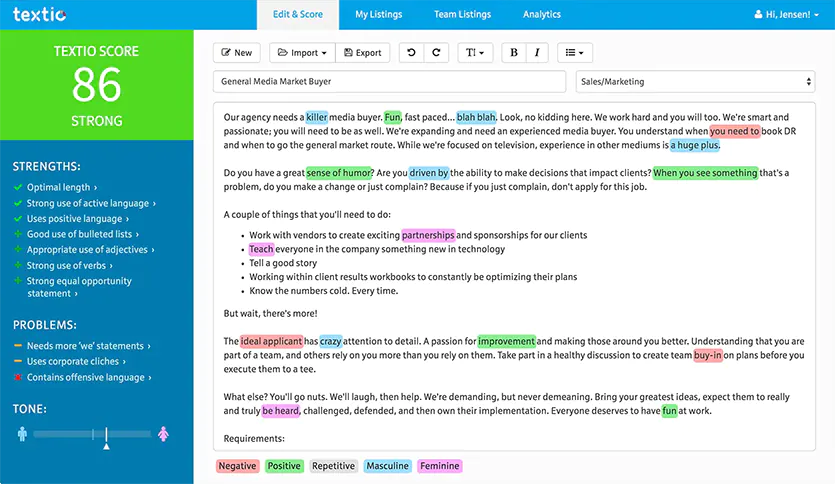
Mehr Transparenz
Die Quintessenz des Posts war aus meiner Sicht die Forderung nach (technischer) Transparenz für maschinell gestützte Systeme und Verfahren, die im Falle von Fehlentscheidungen großen Schaden anrichten können. Automatisierte Bewerber- und Mitarbeiterbewertungen zählen zu solchen “ADM-Systemen” (Algorithmische Entscheidungssysteme).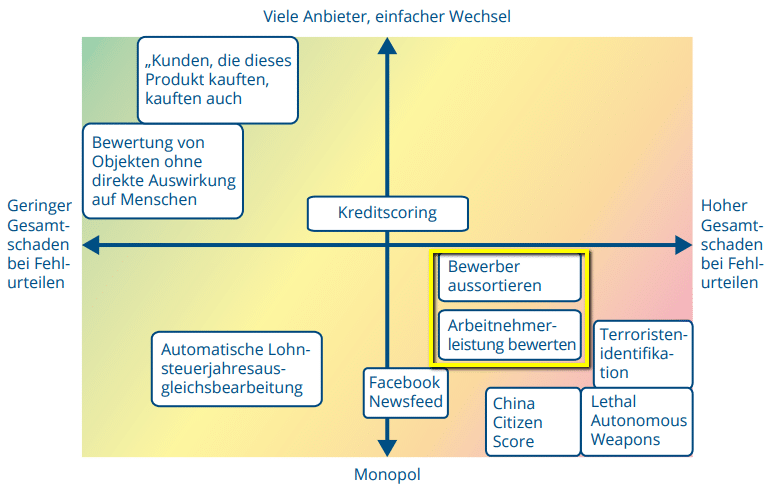
ADM-Riskomatrix von Katharina A. Zweig, Digitale Gesellschaft 338/ Januar 2019
Zu einer sehr ähnlichen Forderungen kommen auch die Forscher der Cornell University in einem kürzlich erschienenem Paper mit dem Titel: “Mitigating Bias in Algorithmic Hiring: Evaluating Claims and Practices”. Diese lesenswerte Arbeit baut auf einer sehr konkreten Untersuchung von real existierenden Anbietern und Lösungen für automatisierte Bewertungs- und Auswahlverfahren. Ich persönlich kenne bis jetzt keine weiteren Untersuchungen dieser Art.
Woher kommen die Daten?
Die Forscher verwenden hier öffentlich zugängliche Angaben von 19 vergleichbaren Unternehmen im Feld und bewerten sie nach den 4 Kriterien: Assesment Typ, Verwendete Daten, Validierung der Ergebnisse und Voreingenommenheit (“Bias”).

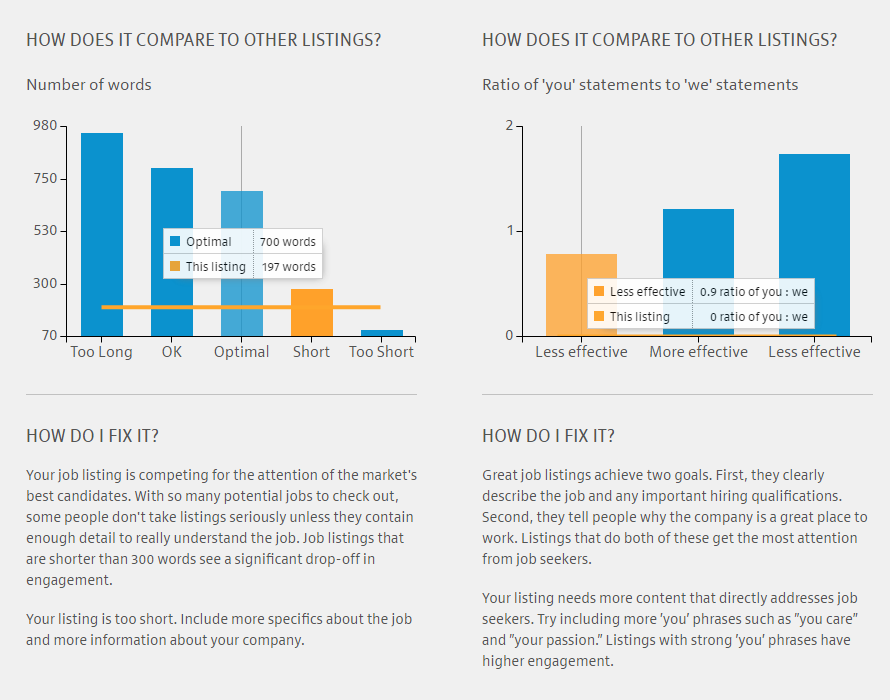
Der spannendste Teil für mich ist die Frage nach den Daten, die als Grundlage für die jeweiligen Verfahren verwendet werden. In der Studie werden drei Optionen unterschieden. “C” – Daten kommen vom Arbeitgeber selbst. “S” – Daten werden passend zum Arbeitgeber “erstellt”. “P” – gleiche (standardisierte) Daten für alle.
Das Problem mit der künstlichen Intelligenz bzw. mit dem maschinellem Lernen ist, dass die Qualität der Ergebnisse äußerst stark von der Menge und der Qualität der für das Training (Lernen) verwendeten Daten abhängt. Passt ein Bewerber, passt er nicht? Um das zu beantworten, müsste bekannt sein, wer früher gepasst UND (idealerweise) wer nicht gepasst hat. Das gleiche Prinzip gilt für Performancebewertungen. Und natürlich sind solche Daten nicht universell einsetzbar. Denn Unternehmen unterscheiden sich erheblich von einander. Richtige Entscheidungen im Unternehmen A können sich als absolut falsch für das Unternehmen B erweisen.
Woher sollen dann die Daten für solche Verfahren nur kommen?! So wie ich unsere Recruiting Welt in den letzten 10+ Jahren kennen gelernt habe, erschließt sich mir die Antwort einfach nicht. Ich kenne keine Unternehmen, die konsistent, sauber über einen langen Zeitraum hinweg relevante (Personal-) Daten erfassen. Daher hege ich, trotz meiner grundlegenden Offenheit technologischen Experimenten gegenüber, eine gewisse Skepsis, wenn es um “intelligentes Matching” irgendeiner Art im Recruiting geht.
###promotional-banner###
Mensch vs. Maschine
Aber sagen wir mal, ich täusche mich an dieser Stelle. Euer Unternehmen ist anders. Ihr habt die letzten 5 Jahre jede Personalentscheidung anhand von 10 Kriterien und einer Skala von 1 bis 10 dokumentiert und auch die Performance der eingestellten Kandidaten ebenfalls konsistent nachvollziehbar beurteilt. Sehr gut. Das zweite Problem versteckt sich in dem “Ihr” – Menschen.
Auch noch so gut systematisch dokumentierte (Personal-) Entscheidungen, die von Menschen getroffen werden, sind voreingenommen. Eine Maschine, die auf Basis dieser Daten trainiert wird, übernimmt zwangsläufig diese Voreingenommenheit. Es ist praktisch gesehen sehr schwer, dagegen effektiv vorzugehen. Dennoch kommen wir Menschen und vor allem die Skeptiker unter uns auf die seltsame Idee, bessere und unvoreingenommene Entscheidungen von automatisierten Bewertungs- und Auswahlverfahren zu erwarten.
Und jetzt wird es ein wenig philosophisch. Warum sollten wir nicht voreingenommene Menschen durch gleichermaßen voreingenommene Maschinen ersetzen? Wenn die Datenbasis solide und sinnvoll ist und die Modelle entsprechend keinen totalen Mist verzapfen, mit welcher Berechtigung betrachten sich dann die Menschen als die funktionsfähigere Alternative? Ich komme an dieser Stelle jetzt völlig durcheinander.
HR Praxis: KI im Recruiting
Egal, wie Ihr zu diesem Thema Mensch vs. Maschine steht. Zwei nützliche Gedanken könntet Ihr hier heute mitnehmen.
1. Saubere, konsistente Daten in Eurem Unternehmen zu erheben, ist keine schlechte Idee. Glaubt man an die Ankunft des KI-Messias, hat man so auf jeden Fall gewonnen. Kommt er nicht, hat man zumindest nix verloren.
2. Wer auch immer Euch etwas mit KI, ML, AI, Matching verkaufen will, lasst Euch bitte glaubhaft erläutern, woher seine Daten kommen, die ausgerechnet auf Euer Unternehmen passen sollen. So viel Transparenz muss sein.