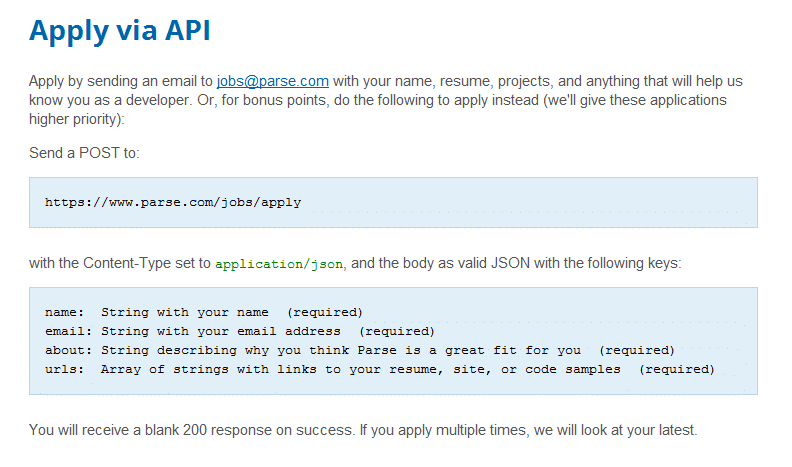
Seit Jahren wurde hier und da spekuliert, warum Google die Jobsuche ignoriert. Keiner hat so viele relevante (Job-) Daten wie Google, keiner hat so viele Ressourcen, um diese Daten sinnvoll weiter zu verarbeiten. Die Abhängigkeit von Google beinahe aller auf Jobsuche spezialisierten Plattformen kann kaum überschätzt werden. Und dennoch schien dieser Bereich für Google in der Vergangenheit völlig uninteressant zu sein.
Cloud Jobs API
Keine zwei Wochen, nachdem Facebook mit der Einführung der Job-Ads plötzlich den Arbeitsmarkt für sich entdeckt hat, offenbart nun auch Google, dass die Jobsuche dem Datenriesen doch am Herzen liegt und man wohl doch nicht geschlafen hat. Mit der “Cloud Jobs API – Job search and discovery powered by machine learning” geht Google allerdings gleich einen ganzen Schritt weiter, als einfach eine weitere Jobbörse auf die Beine zu Stellen.
Google möchte nämlich das sogenannte “Matching” (die Releveanz der Suchergebnisse) verbessern, das sehr viele im Markt in letzter Zeit gerne als Buzzword nutzen. Wirklich gut (bzw. entscheidend besser als Status Quo) hinbekommen hat das allerdings niemand.
Haltet Euch fest. Mit der Clouds Jobs API soll die Jobsuche auf den Karrierewebseiten, in den Stellenbörsen der Bewerbermanagementsysteme und auf Stellenportalen, sprich überall dort, wo nach Jobs gesucht werden kann, entscheidend verbessert werden.
Google hat sich dabei Folgendes überlegt. Die Sprache der Stellenanzeigen stimmt sehr oft nicht mit der Sprache der Jobsuchenden überein. Daher sind die Ergebnisse der Jobsuche oft nicht optimal bzw. muss man lange suchen, bis das Richtige entdeckt wird. Wenn man dazwischen einen guten “Übersetzer” einbaut, würde das Ganze viel besser funktionieren. Angereichert mit künstlicher Intelligenz bzw. lernenden Algorithmen läuft dann die Geschichte immer runder.
Die Technik dahinter
(Diesen Part muss man nicht unbedingt lesen.)
Den Kern des des Mechanismus bilden zwei Ontologien ( 1. Stellenbezeichnungen – mit ca. 30 Kategorien, 1100 Berufsgruppen und 250.00 Berufsbezeichnungen 2. Fähigkeiten/Anforderungen – mit ca. 50.000 Hard- und Soft-Skills). Über relationale Modelle werden sie miteinander “verzahnt”, logische Übereinstimmungen lokalisiert, Zusammenhänge gebildet. Das kann dann so aussehen. Was hängt alles mit einander zusammen… .
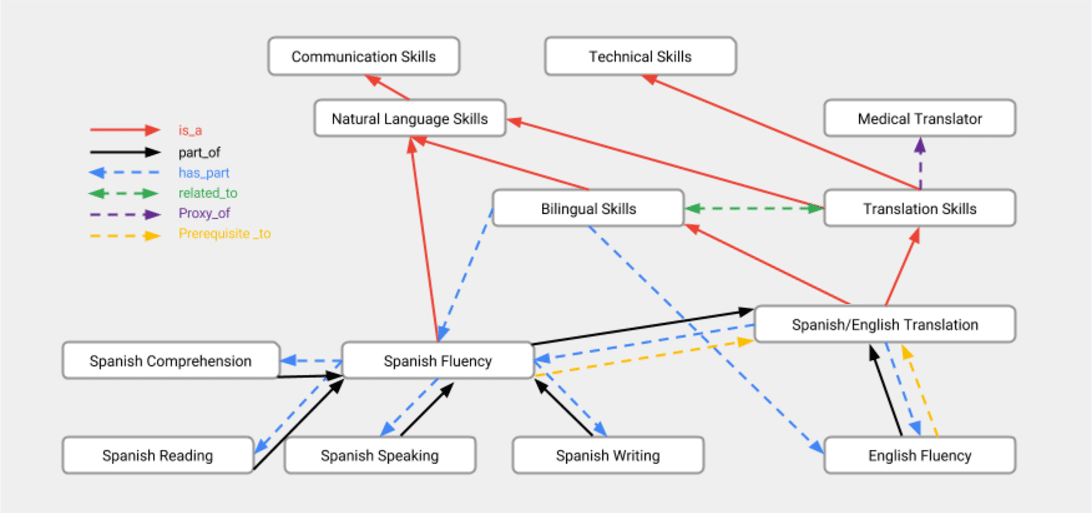
Einen entscheidenden Schritt in dem Prozess stellt die Standardisierung der Jobtitel dar. Um basierend auf dem oben dargestellten Ablauf anschließend passende Vorschläge machen zu können, muss der Algorithmus zunächst so exakt wie möglich verstehen, was gesucht wird. Dazu wird ein Jobtitel “gereinigt” (“gesucht, m/w, ID2368, und sonstiges Zeug” – weg). Über den Abgleich mit einer entsprechend aufgearbeiteten Datenbasis von 17 Mio. Stellenangeboten wird eine bestmögliche Übereinstimmung gesucht.

Features der Cloud Jobs API
In der aktuellen Alpha-Phase unterstützt die API die folgenden Funktionen.
Erweiterung um Synonyme und Akronyme
Die Sucheingabe der Jobsuchenden wir automatisch, um die passenden Synonyme und Akronyme erweitert. Damit wird die Chance erhöht, Stellenangebote zu finden, die eine Sprache verwenden, die sich stark von der des Jobsuchenden unterscheidet.
Anreicherung der Jobdetails
Die Clouds Job API kann die Ausschreibungen mit relevanten Details ergänzen. Fehlen z. B. Adressen, Angaben zur Art der Beschäftigung, weitere übliche Angaben, kann die Ausschreibung automatisch ergänzt werden.
Präzise Geo-Lokalisierung
Unabhängig von der Art und Weise der Adresseingabe in der Stellenausschreibung wird die genaue geographische Position genau interpretiert. Die verbessert wiederum die Suchergebnisse und ermöglicht präzisere Filter.
Prüfung der Aktualität
Die API berücksichtigt das Alter der Ausschreibungen und passt die Suchergebnisse entsprechend an.
Erweiterung der Suchergebnisse in Echt-Zeit
Liefert eine Suchanfrage nicht genug Ergebnisse, z. B. weil die Anfrage zu speziell ist oder sich auf einen sehr kleinen Ort konzentriert, erweitert die API das Spektrum der Ergebnisse unaufgefordert.
Dynamische Empfehlungsfunktion
Der Jobsuchende kann eine Auswahl der ausgegebenen Suchergebnisse priorisieren. Aufbauend auf seinen Präferenzen, wir die Suche weiter verfeinert und er bekommt gegebenenfalls weitere Angebote angezeigt.
Ausblick
Ich persönlich halte diese Nachricht für das Spannendste, was in den letzten Jahren in unserer Branche passiert ist. Schlauer Zug von Google. Zum Einen nimmt man sich mir der Verbesserung der Relevanz der Suchergebnisse genau den Part vor, bei dem alle versagen. Zum Anderen hat sich Google wohl gedacht, Mensch, ich baue einfach die beste Technologie für die Jobsuche, die anderen müssen sie nutzen, und ich kassiere einfach jeden ab. Denn die Google APIs kosten natürlich Geld. Es ist durchaus denkbar, dass ich nicht all zu ferner Zukunft viele etablierte Jobbörsen auf die Google Technologie setzen werden (müssen).
Unabhängig davon kann ich es kaum erwarten, die Technologie auszuprobieren. Man kann sich für die “Limited Preview” anmelden. Und jetzt kommt das große “ABER”. Die Cloud Jobs API unterstützt im Augenblick natürlich nur Englisch als Sprache und das Preview ist nur für Unternehmen in Nord-Amerika möglich. Das ist natürlich zum Weinen. Aber ich hoffe, dass die neue Technologie bald auch uns erreichen wird.
Was ich nochmals explizit unterstreichen möchte, ist die Möglichkeit des Einsatzes der Cloud Jobs API auf Karriereseiten. Die technische Integration soll laut Google relativ einfach sein. Unternehmen mit ein größeren Anzahl von Stellen könnten die Benutzerunfreundlichkeit ihrer Stellenbörsen entscheidend verbessern. Darauf freue ich mich ganz besonders.
Tolle Nachricht. Was denkt Ihr?