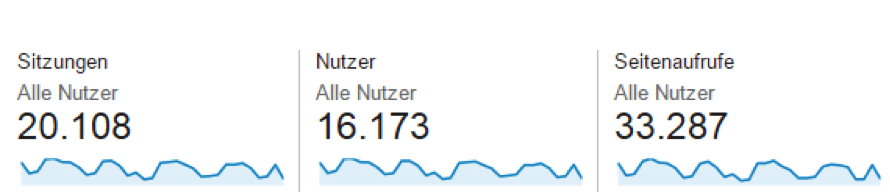
Sitzungen, Nutzer, Seitenaufrufe – gerade Neulinge und Gelegenheitsnutzer in der Welt von Google Analytics haben nach unserer Erfahrung oft Schwierigkeiten, sich in der Begriffswelt dieses Tools zurecht zu finden.
Die Beantwortung der vermeintlich einfachen Frage, wieviele Menschen besuchen nun meine Seite, erweist sich in der Praxis als gar nicht so trivial.
Ist es darüber hinaus erforderlich, eine logische Brücke zu einem weiteren Tracking-System (z. B. einer Werbe-Plattform) zu schlagen, wird’s noch problematischer. Denn dort stößt man auf Begriffe wie Klicks, Website Klicks, Aufrufe, die als Hauptmetrik fungieren (so bei Google AdWords, Facebook Ads usw.), jedoch bei Google Analytics nicht auftauchen.
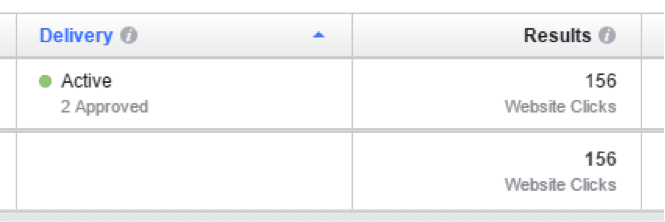
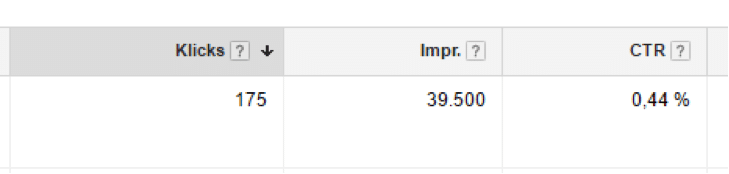
Der Versuch, die “Klicks” aus Google Adwords oder die “Website Clicks” aus Facebook Ads in den Berichten von Google Analytics 1 zu 1 wiederzufinden, scheitert so regelmäßig. Denn Google Analytics verwendet durchgehend die sogenannten “Sitzungen” als Hauptmetrik.
Google Analytics verständlich erklärt
Ein Klick und eine Sitzung sind jedoch zwei fundamental unterschiedliche Konzepte. Dies ist bei Weitem nicht jedem GA-Nutzer bewusst und darüberhinaus nicht einfach zu verinnerlichen. Wir versuchen nun, mithilfe einer einfachen Analogie, etwas mehr Klarheit zu schaffen.
Denkt bitte an Die Fressbude um die Ecke, mit ein paar Tischen, an denen man sich die Speise- sowie die Getränkekarte geben und sich bedienen lassen kann. Du betrittst das Lokal und setzt Dich an den Tisch, der Wirt bemerkt Dich. In der Google Analytics Welt startet in diesem Augenblick eine “Sitzung”.
Ein Sitzung ist für eine begrenzte Zeit aktiv. (Irgendwann weiß der Wirt nämlich nicht mehr genau, dass Du Du bist und kein neuer Gast. Für unsere Analogie nehmen wir der Einfachheit halber bis 00:00 Uhr. Alle Deine Handlungen, die in dieser Zeitspanne stattfinden, sind Bestandteil dieser einen Sitzung, die Dir (dem Gast = “Nutzer”) eindeutig zugeordnet werden kann.
Mehrere Seitenaufrufe pro Sitzung
Du schaust Dir nun die Speisekarte an. Das ist vergleichbar mit einem “Seitenaufruf”.
[su_note note_color=”#fff” text_color=”#000″ radius=”0″]Unser imaginärer Google Analytics Zähler zeigt aktuell an:
1 Sitzung
1 Nutzer
1 Seitenaufruf.
(Ein Gast war heute zu Besuch und hat sich die Speisekarte angeschaut.)
[/su_note]
[promotional-banner id=”43316″]
Nachdem Du die Speisekarte überflogen hast, verlässt Du den Tisch und gehst vor die Tür zum Telefonieren. Nach 5 Minuten kommst Du wieder rein, setzt Dich zurück an Deinen Platz und schaust Dir nun die Getränkekarte an.
[su_note note_color=”#fff” text_color=”#000″ radius=”0″]Unser imaginärer Google Analytics Zähler zeigt aktuell an:
1 Sitzung
1 Nutzer
2 Seitenaufrufe.
(Ein Gast war heute zu Besuch und schaute sich die Speisekarte und anschließend die Getränkekarte an.)[/su_note]
Wichtig: Obwohl Du das Lokal kurz verlassen hast, läuft die ursprüngliche Sitzung weiter. Macht auch irgendwie Sinn. Obwohl Du das Lokal faktisch zwei Mal betreten hast, warst Du ja praktisch an dem besagten Tag nur ein mal zu Besuch.
Man merke sich: Ein Gast kann einem Lokal mehrere Besuche abstatten und dabei jeweils mehrere Handlungen ausüben. Oder in der GA-Welt, ein Nutzer kann einer Webseite mehrere Besuche abstatten und dabei jeweils mehrere Handlungen ausüben.
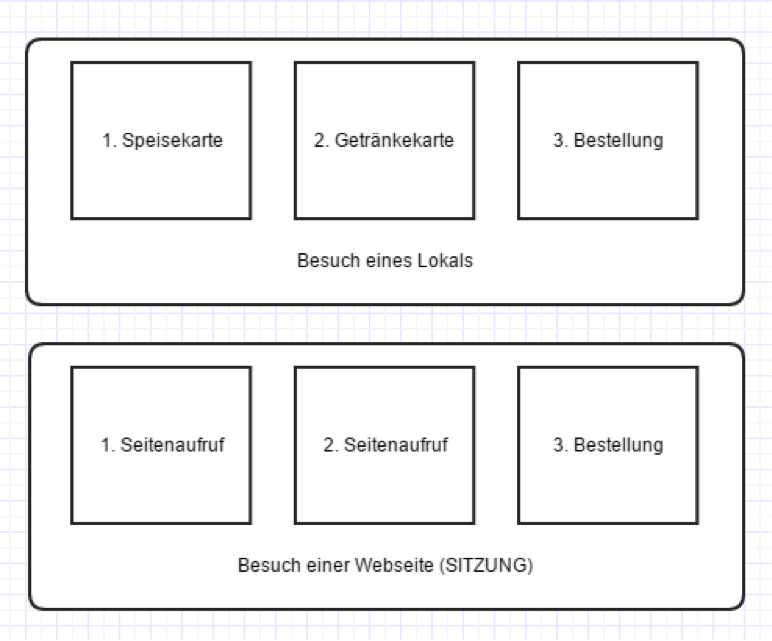
Was ist jetzt ein Klick?
Ok, soweit die Logik von Google Analytics. Doch wie/wo dockt jetzt die Logik mit den “Klicks” an, die von Werbe-Plattformen und anderen Traffic-Lieferanten verwendet wird. Wo finden sich die Klicks in unserer Analogie wieder?
Du gehst morgens an dem besagten Lokal vorbei. Davor steht ein Promoter und drückt Dir einen Werbe-Flyer in die Hand. Er sagt zu Dir, dass wenn Du diesen Flyer dem Wirt zeigst und nach der Getränkekarte fragst, der erste Drink umsonst sei. Du betrittst das Lokal, zeigst den Flyer und fragst nach der Getränkekarte. Der Promoter setzt in seine Strichliste zufrieden einen Strich, denn er wird vom Wirt pro generiertes Interesse bezahlt. Das ist vergleichbar mit dem “Klick” in der Welt der Online-Werbung. Ein Nutzer wurde dazu gebracht, einen ihn interessierenden Inhalt gezielt aufzurufen.
[su_note note_color=”#fff” text_color=”#000″ radius=”0″]Unser Google Analytics Zähler zeigt in dieser Situation:
1 Sitzung
1 Nutzer
1 Seitenaufruf.
Die Werbeplattform X, über die geworben wurde zeigt an: 1 Klick.[/su_note]
Du verlässt nun das Lokal wieder. Läufst um die Ecke und triffst einen weiteren Promoter. Der Wirt hat nämlich mehrere engagiert. Gleiches in Grün. 15 min später bist du mit dem neuen Flyer zurück im Lokal und forderst die Getränkekarte an. Zum zweite Mal wurde Dein Interesse geweckt.
[su_note note_color=”#fff” text_color=”#000″ radius=”0″]Unser Google Analytics Zähler zeigt in dieser Situation:
1 Sitzung
1 Nutzer
2 Seitenaufrufe.
Die Werbeplattform X, über die zum ersten Mal geworben wurde, zeigt an: 1 Klick.
Die Werbeplattform Y, über die zuletzt geworben wurde, zeigt an: 1 Klick.
Der Wirt muss bis jetzt insgesamt für 2 Werbeklicks zahlen.[/su_note]
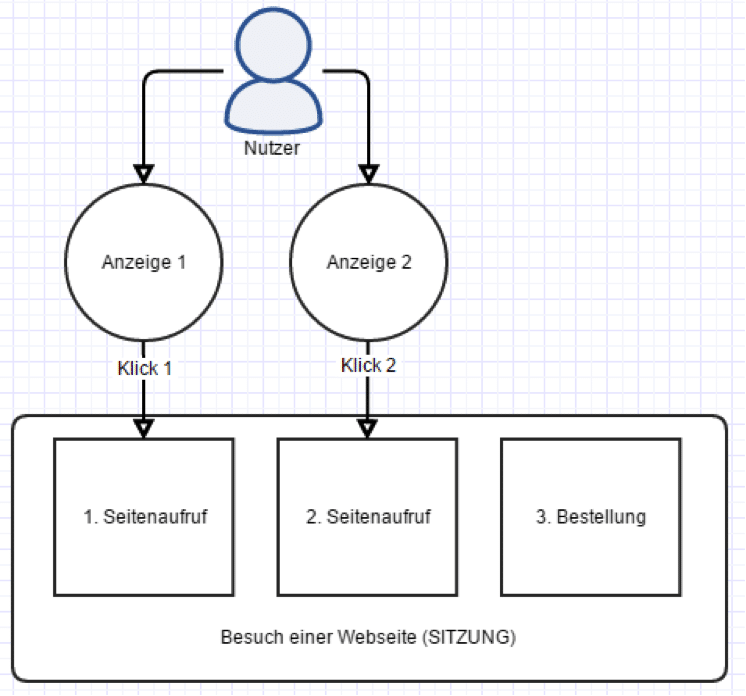
In der Online-Welt könnte die komplette Story so aussehen. Ein potentieller Käufer sucht nach einem Produkt bei Google. Er klickt auf eine Anzeige und landet direkt auf der Produktseite. Er informiert sich, möchte aber das Angebot vergleichen. Er verlässt die Seite und recherchiert weiter. Einige Minuten später gibt er seine Suchanfrage erneut ein (er hat den Namen der Produktseite vergessen), klickt auf die bereits bekannte Anzeige und landet zum zweiten Mal auf der Produktseite, um evtl. den Kauf nun abzuschließen.
[su_note note_color=”#fff” text_color=”#000″ radius=”0″]Im Ergebnis erfasst Google Analytics:
1 Sitzung
1 Nutzer
2 Seitenaufrufe.
Google AdWords erfasst 2 Klicks, die der Werbende bezahlen muss.[/su_note]
Die gleiche Logik gilt auch im Bereich des Klick basierten Personalmarketings, wie im Fall unserer Lösung Jobspreader.
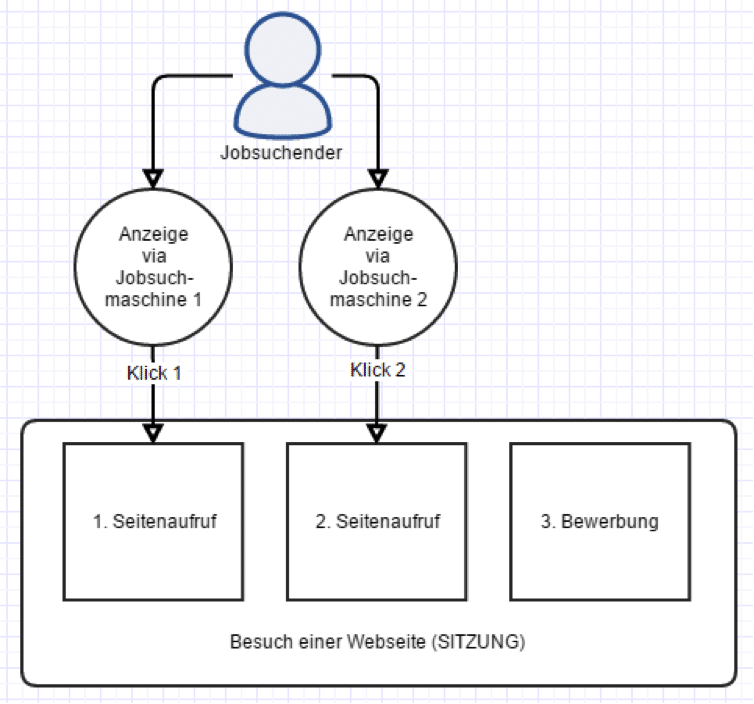
Sitzungen sind keine Klicks!
Merkt Euch: Sitzungen sind keine Klicks! Sitzungen werden in den allermeisten Fällen recht deutlich von den Seitenaufrufen (und Klicks) nach unten abweichen. Wollt Ihr die Klick-Zahlen, die von den Werbeplattformen als Basis für die Abrechnung eingesetzt werden, mit den Google Analytics Zahlen abgleichen, verwendet, falls nichts anderes verordnet, Seitenaufrufe.
###promotional-banner###
Doch auch bei diesem Verfahren werdet Ihr keine 100% Übereinstimmung feststellen können. Aus technischen Gründen ergeben sich immer Unterschiede zwischen verschiedenen Messpunkten. Woran das liegt, werde ich in einem separaten Post erläutern.